主页 > imtoken钱包开发 > 区块链实战学习笔记(二):区块链与工作量证明算法
区块链实战学习笔记(二):区块链与工作量证明算法
综上所述,区块链本质上是一个去中心化的数据库。 它可以提取以下特征:
信息不可修改,加入区块链的信息不可修改; 只支持“增”和“查”操作,与传统数据库技术支持“增、删、查、改”不同,区块链技术只支持“增”操作(即向区块链中添加区块信息),以及“查询”操作(即查询区块链中的区块信息); 不支持“删除”和“修改”操作; 无权限限制,任何加入区块链网络的节点都具有“添加”和“查看”区块信息的权限。
更笼统的了解,可以查看新华社2019年发布的区块链是什么? 你想知道的都在这里!
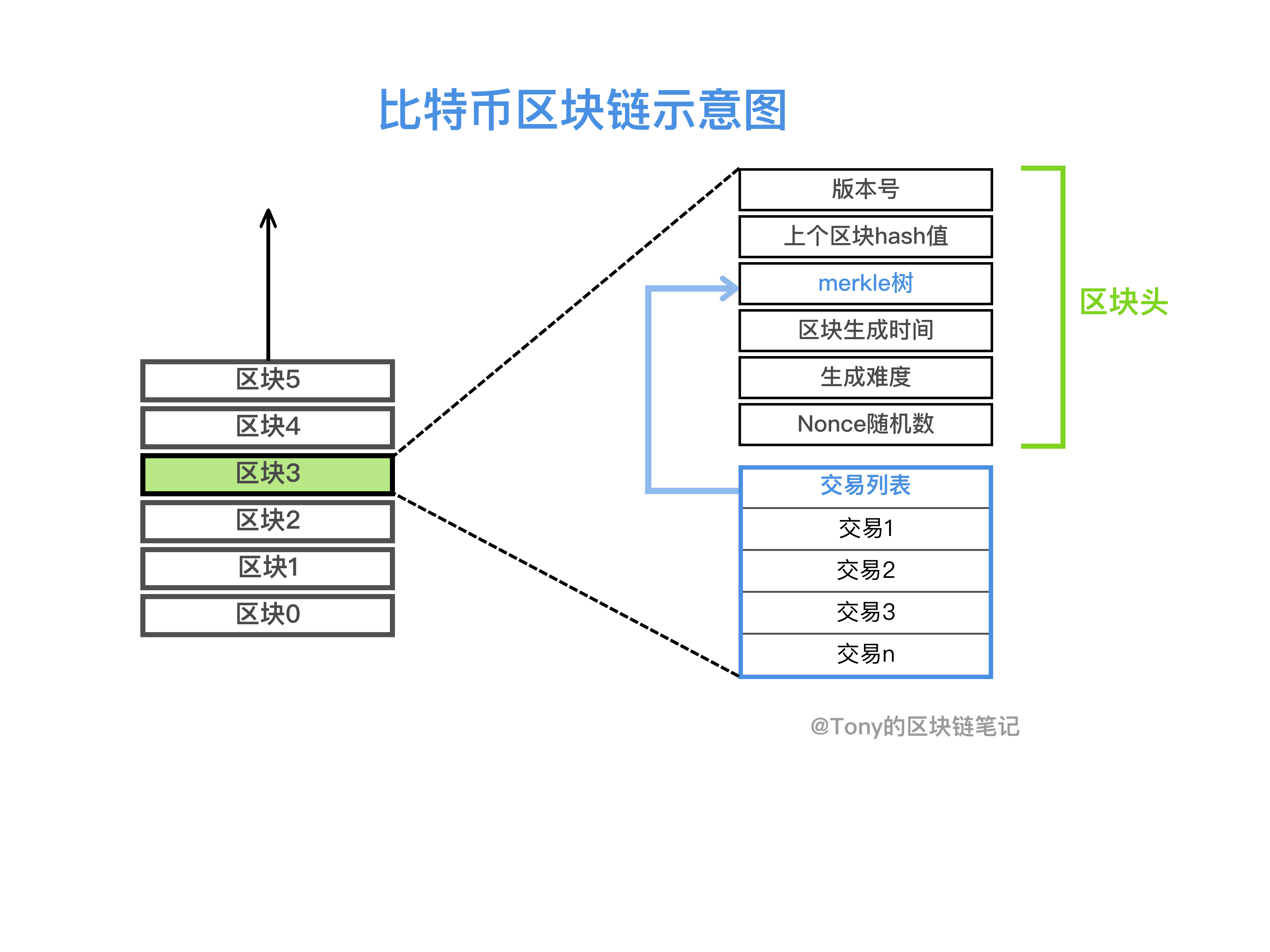
这里直接说说区块链的区块结构,如下表所示:
数据项字节字段说明
魔术号
4个
幻数
常量 0xD9B4BEF9
块大小
4个
块大小
此字段后的块大小(以字节为单位)
大头
80
块头
组成区块头的几个字段描述了区块的元数据
交易柜台
1-9
交易柜台
该区块包含的交易数量,包括coinbase交易,描述紧跟该字段的交易数据数量
交易
不定
贸易
区块中记录的交易信息采用原生的交易信息格式,交易在数据流中的位置必须与Merkle树的叶子节点顺序一致
其中Blocksize和Magic NO都是描述区块链的量词,其余三个概念构成了区块链:

区块头的结构是:
大小域名说明
4字节
版本
版本号,软件升级,指定新版本

32字节
前一个区块哈希
与本区块形成链的前一个区块的哈希值,更确切地说是前一个区块的区块头的哈希值
32字节
默克尔根哈希
这个字段的具体含义解释起来有点复杂,暂时可以理解为区块体的哈希值
4字节
时间戳
可以简单理解为区块创建时的Unix时间戳(即UTC时间1970年1月1日0:00:00到现在的总秒数)
4字节
难度目标
难度调整目标值,后续工作量引入
4字节
随机数
为了找到满足难度目标的随机数,解决32位随机数在算力飙升的情况下不够用的问题,规定可以更改timestamp和coinbase交易信息来扩容随机数位数
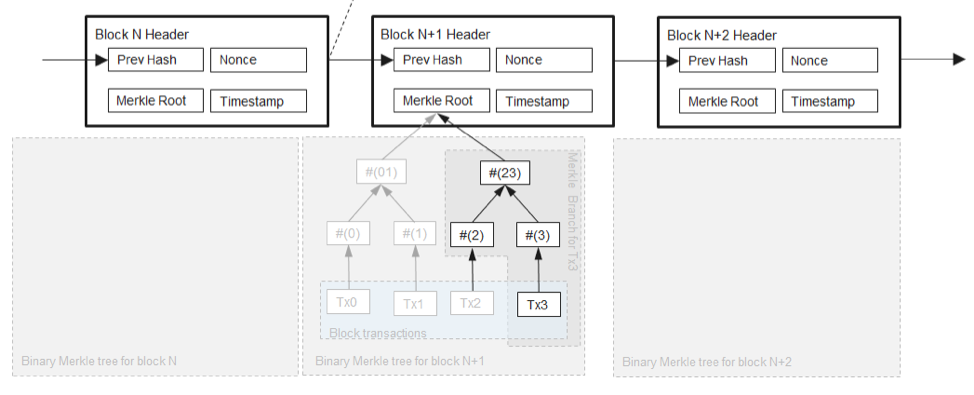
在了解了比特币系统区块头结构中 Previous Block Hash 和 Merkle Root Hash 字段的大致含义后,区块如何形成区块链的具体细节就变得清晰了。
区块链的结构有以下两个主要特点:

这种结构很像数据结构中的链表,如下图所示:

在链表中,初始节点是头节点,而在区块链中,初始块称为Genesis Block,链表的头节点指向Null,因为它本身就是头,Genesis Block 同理,它没有前一个块,所以它的 Previous Block Hash 指向的值是空的。
实现区块类和区块链区块类
基于上一节对区块链结构的分析,我们可以使用Python中的Block类来实现我们第一版区块链的区块。 Block 类包含以下字段:
现场解释
时间戳
当前时间戳,也就是区块创建的时间
上一个区块哈希
前一个块的哈希,父哈希
散列
当前块的哈希
数据
区块中存储的实际有效信息比特币算法原理,即交易
用代码表示为:
class Block(object):
def __init__(self, data, prev_block_hash=''):
self.timestamp = int(time.time())
self.prev_block_hash = prev_block_hash
self.data = data
self.data_hash = hashlib.sha256(data.encode('utf-8')).hexdigest()
代码中的prev_block_hash=''相当于在声明类的时候自动创建一个创世块,它指向一个在python中代表空的字符,使用hashlib中的sha256计算块体和块头的哈希值。
目前我们只是取Block结构的部分字段(Timestamp、Data和PrevBlockHash),将它们拼接在一起,然后对拼接的结果计算一个SHA-256得到一个新的哈希值,也就是与比特币的实现一致:
class Block(object):
......
def hash(self):
data_list = [str(self.timestamp), self.prev_block_hash, self.data_hash]
return hashlib.sha256(''.join(data_list).encode('utf-8')).hexdigest()
......
为了能够打印出可读性更好的Block类,我们为其添加了一个__repr__方法:
class Block(object):
......
def __repr__(self):
s = 'Block(Hash={}, TimeStamp={}, PrevBlockHash={}, Data={}, DataHash={})'
return s.format(self.hash(), self.timestamp, self.prev_block_hash,
self.data, self.data_hash)
至此,一个块类就完成了,可以理解为一种数据结构,类似于单向链表比特币算法原理,但是比单向链表具有更多的功能和携带的信息。
区块链类
如果区块类是单节点行为,而区块链类相当于赋予该类与其他节点通信的权利,区块链类是实现整个区块链系统的主类,所以这里我们直接给出最简单的版本是:
from block import Block
from datetime import datetime
class BlockChain(object):
def __init__(self):
print('Created a new blockchain.\n')
self.chain = []
genesis_block = Block('This is a genesis block')
self.chain.append(genesis_block)
def add_block(self, data):
new_block = Block(data, self.chain[-1].hash())
self.chain.append(new_block)
def print_chain(self):
for block in self.chain:
print('Block Hash: {}'.format(block.hash()))
print('Prev Block Hash: {}'.format(block.prev_block_hash))
print('TimeStamp: {}'.format(datetime.fromtimestamp(block.timestamp)))
print('Data: {}'.format(block.data))
print('')
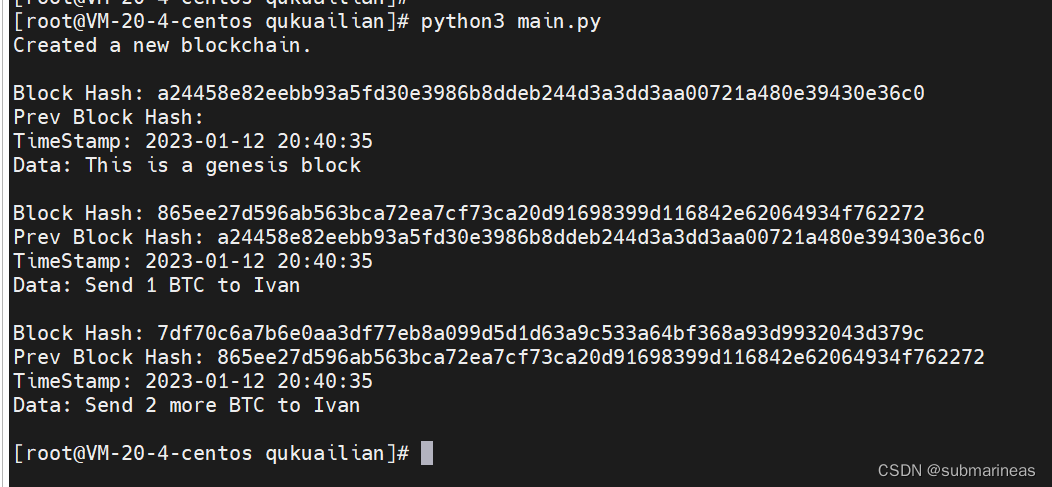
到目前为止,我们已经创建了一个 main 函数来直接调用上面的代码:
from block import Block
from blockchain import BlockChain
if __name__ == '__main__':
# 创建区块链
block_chain = BlockChain()
# 添加第一个区块到区块链中
block_chain.add_block('Send 1 BTC to Ivan')
# 添加第二个区块到区块链中
block_chain.add_block('Send 2 more BTC to Ivan')
# 打印整个区块链的信息
block_chain.print_chain()
输出是:
区块链的功能在这里初步实现了,但是为什么还要用到GPU、分布式等更多的设备呢? 也就是下面要讲的矿工核心算法。
工作量证明算法
在上一节中,我们构建了一个非常简单的数据结构——块,它也是整个区块链数据库的核心。 目前完成的区块链原型已经可以通过链式关系将区块相互关联起来:每个区块都与前一个区块相关联。
然而,按照上述代码实现的区块链有一个巨大的缺陷:在链上添加区块太容易,太便宜。 区块链的一个关键点是,一个人必须经过一系列的艰苦工作才能将数据放入区块链。 正是因为这项艰巨的工作,才保证了区块链的安全性和一致性。 另外,完成这项工作的人也会获得相应的奖励(这是通过挖矿获得币)。
这种机制与生命现象非常相似:一个人必须努力工作才能获得回报或奖励来维持自己的生命。 在区块链中,整个网络是由网络中的参与者(矿工)的持续工作支撑的。 矿工不断向区块链添加新的区块,然后获得相应的奖励。 在这种机制的作用下,新产生的区块可以安全地加入到区块链中,维护了整个区块链数据库的稳定性。 值得注意的是,做这个工作的人必须证明这一点,即他必须证明他确实做过这些工作。
整个“努力工作并证明”机制称为工作量证明。
工作流程证明
工作量证明的核心思想是为向区块链添加新区块的操作设置一定的难度。 每个人都有权在区块链中添加新的区块,但并不是每个人都有能力这样做,并且必须付出一定的代价,这就是工作量证明。
如何设置“添加新区块到区块链”操作的难度? 其实也很简单,就是规定新区块的区块头的哈希值必须满足一定的特征。 由于哈希值的“单向性”和“雪崩效应”,计算机只能通过穷举计算得到具有一定特征的哈希值,而工作量证明算法就是穷举计算哈希值的过程:

这种计算哈希值的详尽过程在比特币系统中也称为挖矿。 比特币实现要求的新区块的区块头哈希值的特点是哈希值必须是一定数量的前导0。 前导零的数量称为挖矿难度。 该值越大,挖矿难度越大(即找到一个可以添加到比特币区块链的新区块所需的时间越长)。 在比特币区块头结构中,有两个与挖矿相关的字段:
大小域名说明
4字节
难度目标
表示当前挖矿难度,但这个值并不直接表示前导0的个数,而是经过特殊编码处理后的一个值。 计算方法如下图所示
4字节
随机数
为了找到满足难度目标的随机数,解决32位随机数在算力飙升的情况下不够用的问题,规定可以更改timestamp和coinbase交易信息来扩容随机数位数
关于Difficulty Target,在表格中已经说明的很清楚了。 需要注意的是,这里的nonce是区块中的nonce,主要是调整挖矿难度; 每笔交易也有一个nonce,每个外部账户(key控制的私密账户)都有一个nonce值,从0开始不断累加,每一次累加代表一次交易。 关于后者,我们将在会后介绍。
所以我们可以更新块类中的 hash 方法以将 Nonce 添加到列表中:
import time
import hashlib
class Block(object):
def __init__(self, data, prev_block_hash=''):
self.timestamp = int(time.time())
self.prev_block_hash = prev_block_hash
self.data = data
self.nonce = 0 # 添加 nonce 成员,初始值为 0
self.data_hash = hashlib.sha256(data.encode('utf-8')).hexdigest()
def hash(self): # 计算散列值时,同样加入 nonce值
data_list = [str(self.nonce),str(self.timestamp),
self.prev_block_hash, self.data_hash]
return hashlib.sha256(''.join(data_list).encode('utf-8')).hexdigest()
def __repr__(self): # 打印输出,同样加入 nonce值
return 'Block(Hash={}, TimeStamp={}, PrevBlockHash={}, Nonce={}, \
Data={}, DataHash={})'.format(self.hash(), self.timestamp,
self.prev_block_hash, self.nonce, self.data, self.data_hash)
然后定义工作负载的 nonce 和 difficulty_bits:
class ProofOfWork(object):
MAX_NONCE = sys.maxsize
def __init__(self, difficulty_bits=12):
self._target = 1 << (256-difficulty_bits)
这里MAX_NONCE用于在求解nonce值时限制上限。 sys.maxsize 与操作系统有关。 如果是32位操作系统,那么这个值就是2^31-1,就是2147483647。如果是64位,就是2^63-1,就是9223372036854775807
difficulty_bits的计算规则如下:

可能会看到 1 在左边





